Penulis : Endin Fahrudin,ST,.MKom
Program Studi Sistem Informasi Fakultas Ilmu Komputer Univeritas Pamulang
1. Pendahuluan
Dalam era transformasi digital, sebagian besar data yang dihasilkan berbentuk teks tidak terstruktur—mulai dari unggahan media sosial, laporan medis, hingga dokumen hukum. Namun, komputer tidak memahami teks sebagaimana manusia memahaminya. Agar algoritma Machine Learning atau Deep Learning dapat bekerja secara optimal, data teks mentah harus melewati fase krusial yang disebut Text Pre-processing.
Secara fundamental, pre-processing bertujuan untuk mengurangi variasi teks yang tidak perlu dan menghilangkan “noise” (gangguan) agar model dapat fokus pada pola makna yang sebenarnya. Tanpa tahap ini, model akan mengalami overfitting atau menghasilkan prediksi yang tidak akurat karena memproses informasi yang tidak relevan.
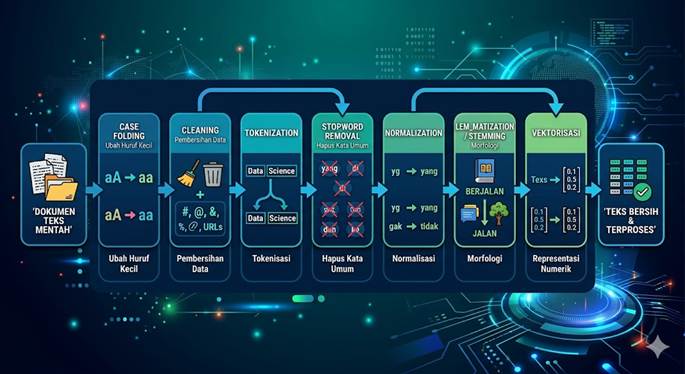
2. Tahapan Utama Pre-processing
Proses pengolahan teks biasanya mengikuti alur kerja sistematis. Berikut adalah langkah-langkah standar yang digunakan dalam industri dan riset:
A. Case Folding
Tahap paling sederhana namun penting. Tujuannya adalah mengubah seluruh huruf dalam dokumen menjadi format yang sama, biasanya huruf kecil (lowercase).
- Contoh: “Belajar Data Science” → “belajar data science”.
- Urgensi: Menghindari sistem menganggap “Data” dan “data” sebagai dua entitas yang berbeda.
B. Cleaning (Pembersihan Data)
Menghapus komponen yang tidak memberikan nilai informatif bagi analisis teks. Hal ini meliputi:
- Penghapusan tanda baca (punctuation).
- Penghapusan angka yang tidak relevan.
- Penghapusan URL, HTML tags, dan karakter khusus/emoji.
- Penghapusan whitespace (spasi berlebih).
C. Tokenization (Tokenisasi)
Proses memecah sekumpulan teks menjadi potongan-potongan kecil yang disebut token. Token bisa berupa kata, frasa, atau karakter.
- Sentence Tokenization: Memecah paragraf menjadi kalimat.
- Word Tokenization: Memecah kalimat menjadi kata-kata penyusunnya.
D. Filtering (Stopword Removal)
Menghapus kata-kata umum yang sering muncul namun memiliki bobot informasi yang sangat rendah dalam analisis frekuensi.
- Contoh (Bahasa Indonesia): “yang”, “di”, “ke”, “dari”, “adalah”.
- Manfaat: Mengurangi ukuran dataset dan mempercepat waktu komputasi.
E. Normalization (Normalisasi)
Mengubah kata-kata tidak baku menjadi kata baku sesuai kamus (seperti KBBI).
- Contoh: “yg” → “yang”, “gak” → “tidak”, “bgt” → “banget”.
3. Transformasi Morfologis: Stemming vs Lemmatization
Dua teknik ini sering membingungkan, namun memiliki perbedaan mekanis yang signifikan:
- Stemming: Memotong imbuhan secara kasar untuk mendapatkan kata dasar (root word). Algoritma populer di Indonesia adalah Nazief & Adriani.
- Contoh: “Memakan” → “makan”.
- Lemmatization: Mengembalikan kata ke bentuk kamusnya (lemma) berdasarkan analisis linguistik dan konteks (POS-tagging). Lemmatization jauh lebih akurat namun membutuhkan komputasi lebih tinggi dibanding Stemming.
4. Representasi Teks ke Vektor (Vectorization)
Setelah teks menjadi bersih dan terstandardisasi, tahap terakhir adalah mengubahnya menjadi representasi numerik agar dapat diproses oleh algoritma matematika.
| Teknik | Penjelasan Singkat |
| Bag of Words (BoW) | Menghitung frekuensi kemunculan setiap kata tanpa mempedulikan urutan. |
| TF-IDF | Memberikan bobot lebih besar pada kata yang unik dan penting dalam sebuah dokumen dibanding kata yang muncul di seluruh dokumen. |
| Word Embeddings | Representasi kata dalam ruang vektor dimensi tinggi (misalnya Word2Vec, GloVe) yang menangkap hubungan semantik. |
5. Tantangan dan Kesimpulan
Pengolahan data teks di Indonesia memiliki tantangan tersendiri, terutama pada penggunaan bahasa prokem (gaul), singkatan yang tidak konsisten, dan struktur morfologi yang kompleks.
Kesimpulan:
Pre-processing bukan sekadar langkah opsional, melainkan fondasi dari efektivitas model NLP. Kualitas input yang bersih akan berbanding lurus dengan kualitas output prediksi. Dalam riset akademis maupun implementasi industri, pemilihan m